近似对数概率近似#
最后更新:2025年11月19日
概述#
近似对数概率(Proximal log-probability approximation)是一种用于解耦PPO的优化技术,消除了计算近端策略对数概率以进行重要性比率计算所需的昂贵前向传播。
在解耦PPO(离策略PPO)中,我们使用三个策略计算重要性比率:
π_behave:行为策略(生成样本的策略)
π_proximal:近端策略(当前策略落后一步的策略)
π_θ:当前策略(正在优化的策略)
标准解耦PPO需要每步通过完整前向传播重新计算π_proximal。此特性近似π_proximal,使用版本感知插值在缓存的π_behave和计算的π_θ之间进行:
其中 \(v\) 表示生成每个token时的策略版本。
性能优势#
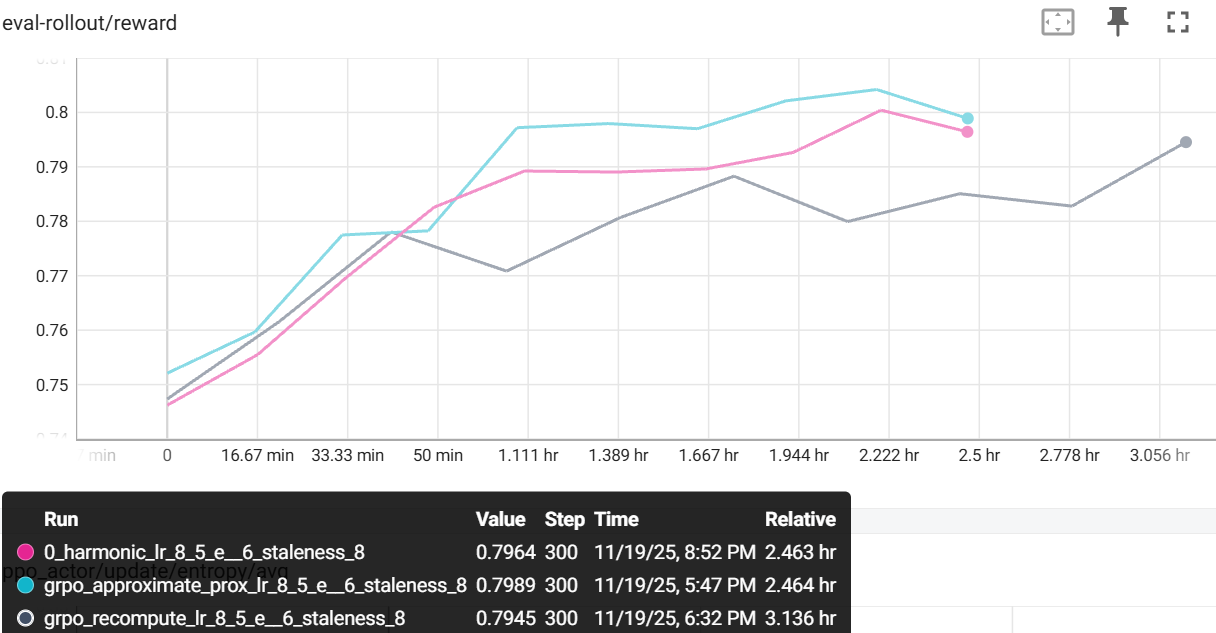
训练速度快27%:每步节省一次完整前向传播(300步用时163分钟对比207分钟)
更好的评估奖励:在GSM8K上达到0.799对比0.795
任务奖励相当:0.937对比0.954(在2%以内)
用户脚本零更改:自动与现有解耦PPO代码配合工作
核心参数#
actor.use_decoupled_loss:必须设为true才能启用解耦PPO(近似所需)actor.prox_logp_method:计算近端策略对数概率的方法(默认:"recompute")"recompute":标准解耦PPO,通过前向传播重新计算近端策略"loglinear":使用对数线性插值近似近端策略(快速,推荐)"metrics":类似recompute,但也计算近似指标以供评估
示例用法#
生产配置(最大速度)#
actor:
use_decoupled_loss: true
prox_logp_method: loglinear # 启用近似,跳过前向传播
运行命令:
python examples/math/gsm8k_rl.py \
--config examples/experimental/prox_approx/gsm8k_grpo_prox_approx.yaml \
scheduler.type=local
评估配置(带指标)#
actor:
use_decoupled_loss: true
prox_logp_method: metrics # 计算真实值 + 近似指标
更多示例见 examples/experimental/prox_approx/。
基线#
基于使用Qwen2.5-1.5B-Instruct在GSM8K上的实验:
设置:
训练步数:300
样本陈旧度:8步(离策略场景)
模型:Qwen2.5-1.5B-Instruct
数据集:GSM8K
方法 |
训练时间 |
最终任务奖励 |
最终评估奖励 |
加速比 |
|---|---|---|---|---|
标准解耦PPO(重新计算) |
207分钟 |
0.954 |
0.795 |
1.0×(基线) |
+ 近似(loglinear) |
163分钟 |
0.937 |
0.799 |
1.27× |
+ 近似(linear) |
~163分钟 |
0.944 |
0.796 |
1.27× |
关键发现:
快27%:两种近似方法在300步中节省约44分钟
loglinear方法:最佳评估奖励(0.799),任务奖励略低(0.937)。概率空间中的对数空间线性插值。
linear方法:更好的任务奖励(0.944),匹配基线评估奖励(0.796)。概率空间中的线性插值,然后转换为对数空间。
性能相当:两种方法在所有指标上与重新计算基线相差在2%以内
训练稳定:8步陈旧度的平滑收敛(离策略场景)
已被证明有效:在现实离策略场景中效果良好
更多详情#
近似方法#
"loglinear"(推荐)
公式:$\log \pi_{prox} = \log \pi_{behave} + \alpha \cdot (\log \pi_{\theta}
\log \pi_{behave})$
对数空间中的线性插值(概率空间中的几何平均)
简单、快速、稳定
最佳评估奖励(GSM8K上0.799)
在Qwen2.5-1.5B-Instruct的GSM8K上已被证明有效
"linear"(替代方案)
公式:\(\log \pi_{prox} = \log[(1-\alpha) \cdot \pi_{behave} + \alpha \cdot \pi_{\theta}]\)
概率空间中的线性插值(算术平均),然后转换为对数空间
更好的任务奖励(GSM8K上0.944)
在Qwen2.5-1.5B-Instruct的GSM8K上也被证明有效
"rollout"(指标基线)
公式:\(\log \pi_{prox} = \log \pi_{behave}\)
直接使用行为策略作为近端策略(无插值)
仅在内部用于
prox_logp_method="metrics"时的指标比较不可作为用户可用的配置选项(类似行为请使用
use_decoupled_loss=false)
配置逻辑#
use_decoupled_loss?
├─ No → 标准PPO(近似不可用)
└─ Yes → 启用解耦PPO
└─ prox_logp_method?
├─ "recompute" → 标准解耦PPO(通过前向传播重新计算π_proximal)
├─ "loglinear" → 生产模式(使用近似,跳过前向传播)
└─ "metrics" → 评估模式(重新计算π_proximal + 计算近似指标)
指标说明#
无论 prox_logp_method 如何,指标始终记录在 ppo_actor/update/compute_logp/ 下。确切指标取决于模式:
重新计算模式(prox_logp_method="recompute")#
prox_logp_gt/avg:真实近端对数概率(重新计算的)
Loglinear模式(prox_logp_method="loglinear")#
prox_logp_gt/avg:真实近端对数概率(重新计算的,当可用时)loglinear/approx_logp/avg:近似近端对数概率loglinear/behave_imp_weight/avg:π_prox / π_behave(近似的)loglinear/importance_weight/avg:π_θ / π_prox(近似的)
指标模式(prox_logp_method="metrics")#
真实值:
prox_logp_gt/avg:真实近端对数概率
每种方法的指标(分别针对 loglinear/、linear/、rollout/):
对数概率指标:
{method}/approx_logp/avg:近似对数概率{method}/abs_error/avg:与真实值的绝对误差{method}/rel_error/avg:相对误差(%){method}/squared_error/avg:平方误差
行为重要性权重(π_prox / π_behave):
{method}/behave_imp_weight/avg:近似比率{method}/behave_imp_weight_abs_error/avg:绝对误差{method}/behave_imp_weight_rel_error_/avg:相对误差(%)
重要性权重(π_θ / π_prox):
{method}/importance_weight/avg:近似比率{method}/importance_weight_abs_error_/avg:绝对误差{method}/importance_weight_rel_error_/avg:相对误差(%)
典型良好值:
对数概率绝对误差:0.001-0.01
对数概率相对误差:0.1%-1%
重要性权重绝对误差:0.001-0.01
重要性权重相对误差:0.1%-1%
何时使用#
✅ 推荐:
生产级解耦PPO训练
中等陈旧度的离策略场景(1-5步更新)
前向传播昂贵的大规模训练
使用指标验证近似质量后
⚠️ 谨慎使用:
高样本陈旧度(>10步更新)——密切监控指标
不稳定的策略更新——近似假设平滑变化
训练初期——策略快速变化
❌ 不使用:
标准on-policy PPO(不适用)
需要精确值的调试模式
前向传播已经很快的情况(小模型)
实现说明#
版本跟踪: 每个生成的token都携带一个版本号,指示是哪个策略版本生成的它。近似使用这些版本来计算插值权重α。
自动优化: 当 prox_logp_method="loglinear" 时,前向传播在 compute_logp() 中自动跳过,用户脚本无需任何更改。
安全检查:
检查近似值中的NaN/Inf
确保在需要时版本可用
为配置错误提供清晰的错误消息