二阶矩信任策略优化 (M2PO)#
最后更新:2025年10月23日
作者:Jingyuan Ma
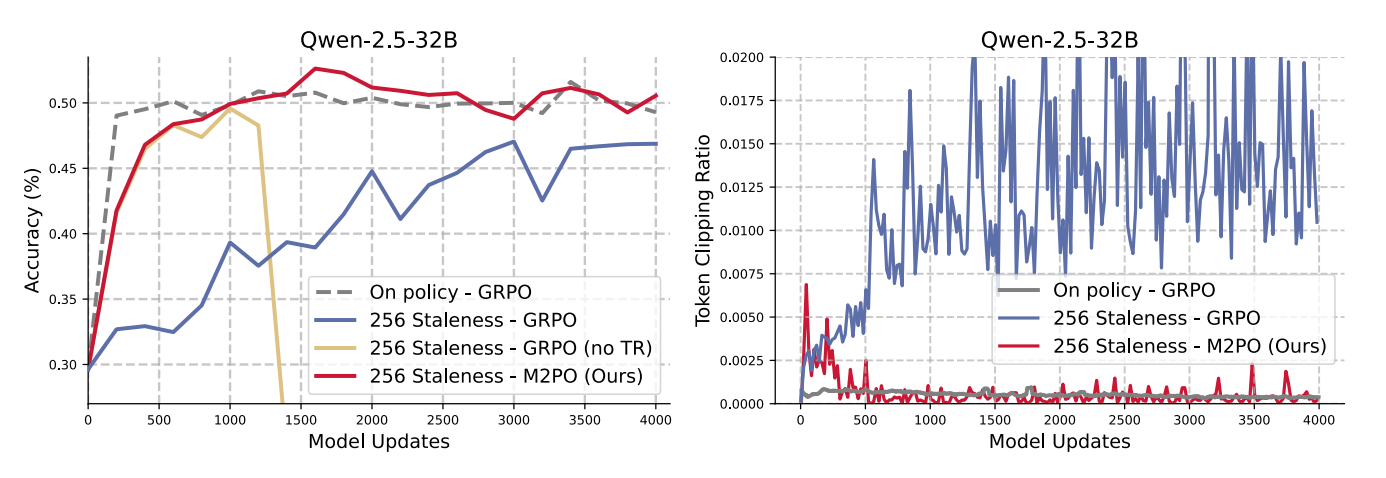
二阶矩信任策略优化 (M2PO)(Zheng et al., 2025)是一种RL方法,即使数据至少落后256个模型更新也能实现稳定的离策略训练,并通过约束重要性权重的二阶矩来抑制极端异常值同时保留信息丰富的更新,从而匹配on-policy性能。
M2PO的第一步是计算二阶矩: $\( \hat{M_2}=\frac{1}{N}\sum_{i=1}^NM_{2,i}=\frac{1}{N}\sum_{i=1}^N(\log{r_i})^2=\frac{1}{N}\sum_{i=1}^N\left(\log\frac{\pi_\theta (a_i|s_i)}{\pi_{behav}(a_i|s_i)}\right)^2 \)$
第二步是计算二阶矩掩码:

最后一步是优化目标:
其中 \(M\) 在第二步中计算,且
更多详情:
核心参数#
actor.m2_threshold:二阶矩均值的阈值,用于计算M2PO掩码,形式为 \(\tau_{M_2}\)
示例用法#
我们建议在配置文件中修改参数(即gsm8k_m2po.yaml)。
后端 |
CMD |
|---|---|
local |
|
ray |
|
slurm |
|
测试结果#
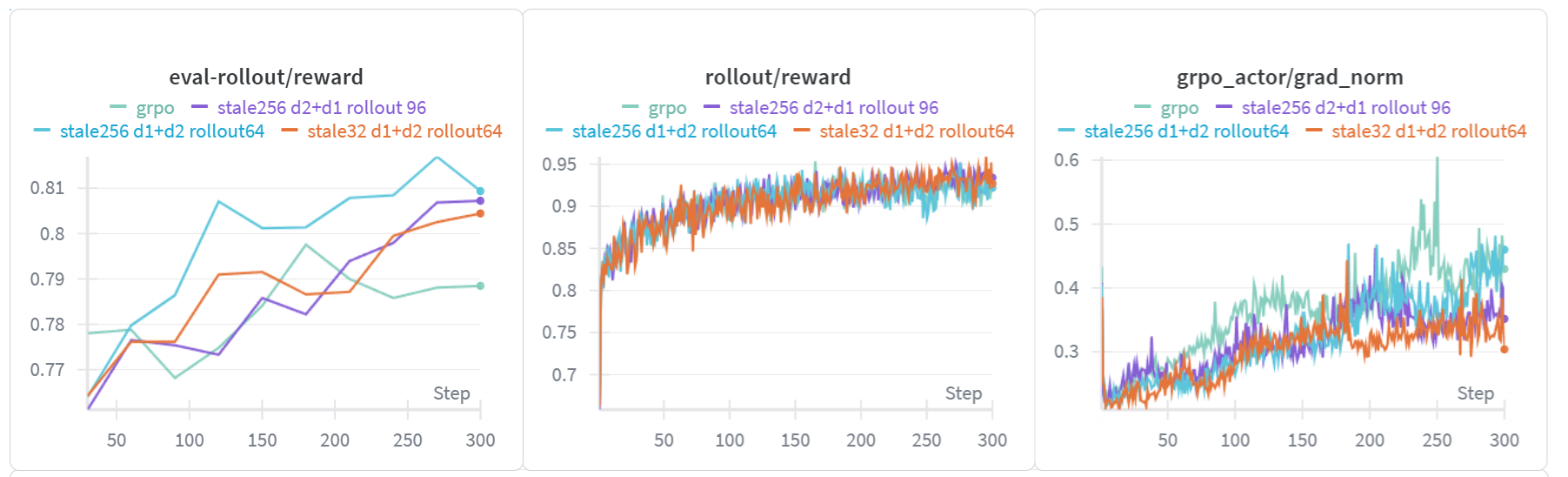
在本测试中,我们按以下规则命名实验:
stale:
max_head_offpolicyness的值dx+dy:x为rollout worker数量,y为训练worker数量
rollout:
max_concurrent_rollout的值
GRPO的设置为stale 256 d2+d1 rollout 96
实验的关键发现如下:
GRPO的
grad_norm高于M2PO,这可能导致训练不稳定。M2PO的评估奖励高于GRPO。