On-Policy Distillation#
概述#
On-policy distillation 使用教师模型在学生当前策略采样的轨迹上进行指导,从而减少分布偏移并提升训练稳定性。与强化学习结合后,学生可以在探索的同时进行教师模仿。
AReaL 之前主要支持 RL 后训练;本实现增加了 on-policy 知识蒸馏 与 KDRL 联合框架,使学生可以在同一批 on-policy 轨迹上同时“向教师学习 + 通过 RL 探索”,提升效率与稳定性。
核心思想#
知识蒸馏的目标是让学生策略 \(\pi_\theta\) 拟合更强教师 \(\pi_T\) 的行为。蒸馏目标中采用的散度形式与采样分布,会显著影响学生的最终表现与 exposure bias。
监督微调(Forward KL)#
一种简单有效的方法是在教师生成的数据上最大化对数似然,即 SFT。这等价于最小化 \(\pi_T\) 与 \(\pi_\theta\) 之间的 Forward KL:
On-Policy Distillation(Reverse KL)#
虽然 SFT 高效,但在 off-policy 数据上训练会产生 exposure bias:训练时是教师前缀,推理时是学生自回归前缀。对长链路推理模型此问题尤为明显。为缓解该问题,可在学生自采样轨迹上训练,这等价于最小化 Reverse KL(RKL)[1]:
最小化 RKL 可视为一种 REINFORCE:奖励是教师与学生概率的对数比。采用 GRPO 框架时优化目标为 [1]:
其中奖励为 \(R_{i,t} = \log \pi_T(o_{i,t}) - \log \pi_\theta(o_{i,t})\)。这会提升教师偏好 token 的概率,并抑制教师认为不合理的 token。
实现细节:纯 KD 场景下需将
rl_loss_weight设为 0。实现会用重要性采样估计 RKL 梯度。代码中以teacher_logp - logprobs作为奖励(\(R_{i,t}\)),并通过负号系数将目标转为最小化(见areal/trainer/ppo/actor.py)。
GRPO 与 KD 联合#
我们实现了 KD+RL 的 Joint Loss 方案。
Joint Loss#
该方案在 GRPO 目标上增加辅助 KL 项。为保持与 GRPO 的 on-policy 特性一致,这里使用 Reverse KL(RKL)[1]:
\(\nabla_\theta J_{KDRL}(\theta)\) 是 \(\nabla_\theta J_{GRPO}( \theta) + \beta \cdot \nabla_\theta J_{RKL}(\theta)\) 的无偏估计。
实现细节:在联合损失场景(
rl_loss_weight> 0)中,RKL 作为直接正则项。最小化logprobs - teacher_logp,在学生分布 \(\pi_\theta\) 采样下与最小化 \(D_{KL}(\pi_\theta \parallel \pi_T)\) 等价。代码实现为:loss = rl_loss_weight * loss + distill_loss_weight * rkl_penalty
运行示例#
在 YAML 中加入 teacher 配置:
teacher:
backend: fsdp:d1p1t4
rl_loss_weight: 1.0
distill_loss_weight: 0.005
experiment_name: ${experiment_name}
trial_name: ${trial_name}
path: Qwen/Qwen3-32B
init_from_scratch: false
disable_dropout: true
dtype: ${actor.dtype}
mb_spec:
max_tokens_per_mb: 10240
optimizer: null
scheduling_spec: ${actor.scheduling_spec}
本地调度器示例命令:
python3 examples/math/gsm8k_rl.py --config examples/distillation/gsm8k_grpo_distill.yaml scheduler.type=local experiment_name=gsm8k-grpo-distillation trial_name=trial0
结果#
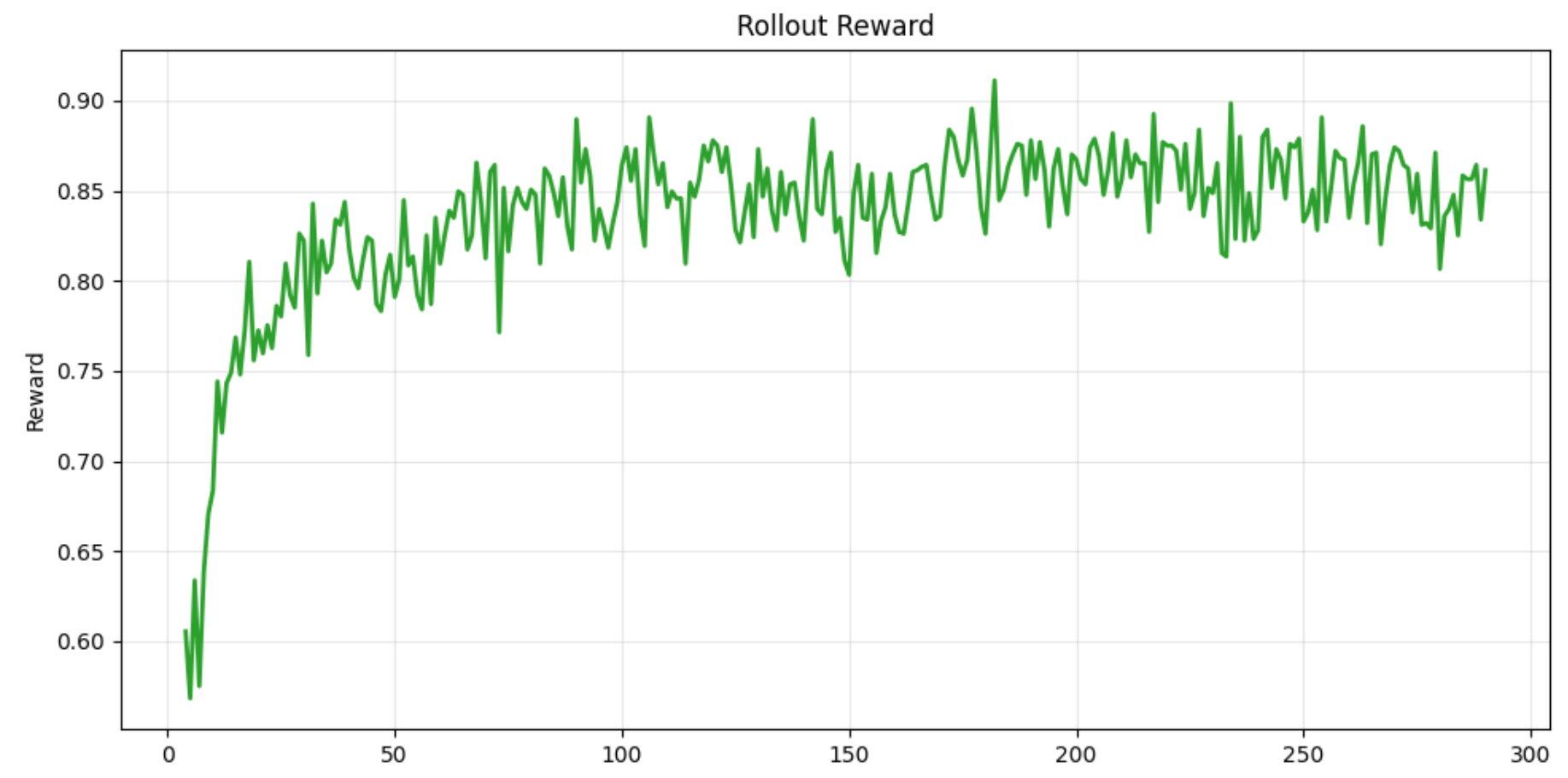
下图为 Qwen2.5-14B-Instruct(教师)与 Qwen3-0.6B(学生)在 FSDP + vLLM 条件下的 on-policy KD + RL 奖励曲线。
参考#
[1] Xu H, Zhu Q, Deng H, Li J, Hou L, Wang Y, Shang L, Xu R, Mi F. Kdrl: Post-training reasoning llms via unified knowledge distillation and reinforcement learning. KDRL paper link