The Community Stories of vLLM and SGLang

Originally published on Medium by Ant Open Source.
First, what is LLM inference?
Training large language models (LLMs) attracts attention for its massive compute demands and headline-making breakthroughs; however, what ultimately determines their real-world practicality and broad adoption is the efficiency, cost, and latency of the inference stage. Inference is the process by which a trained AI model applies what it has learned to new, unseen data to make predictions or generate outputs. For LLMs, this means accepting a user prompt, computing through the model's vast network of parameters, and ultimately producing a coherent text response.
The core challenge in LLM inference is deploying models with tens to hundreds of billions of parameters under tight constraints on latency, throughput, and cost. It is a complex, cross-stack problem spanning algorithms, software, and hardware. Among open-source inference engines, vLLM and SGLang are two of the most closely watched projects.
From academic innovation to a community-driven open-source standard-bearer

vLLM traces its roots to a 2023 paper centered on the PagedAttention algorithm, "Efficient Memory Management for Large Language Model Serving with PagedAttention." vLLM's breakthrough wasn't a brand-new AI algorithm; instead, it borrowed paging and cache management ideas from operating systems to fine-grain memory management, laying the groundwork for high-throughput request handling via its PagedAttention mechanism. vLLM also embraced and advanced several industry techniques, such as Continuous Batching first described in the paper "Orca: A Distributed Serving System for Transformer-Based Generative Models."
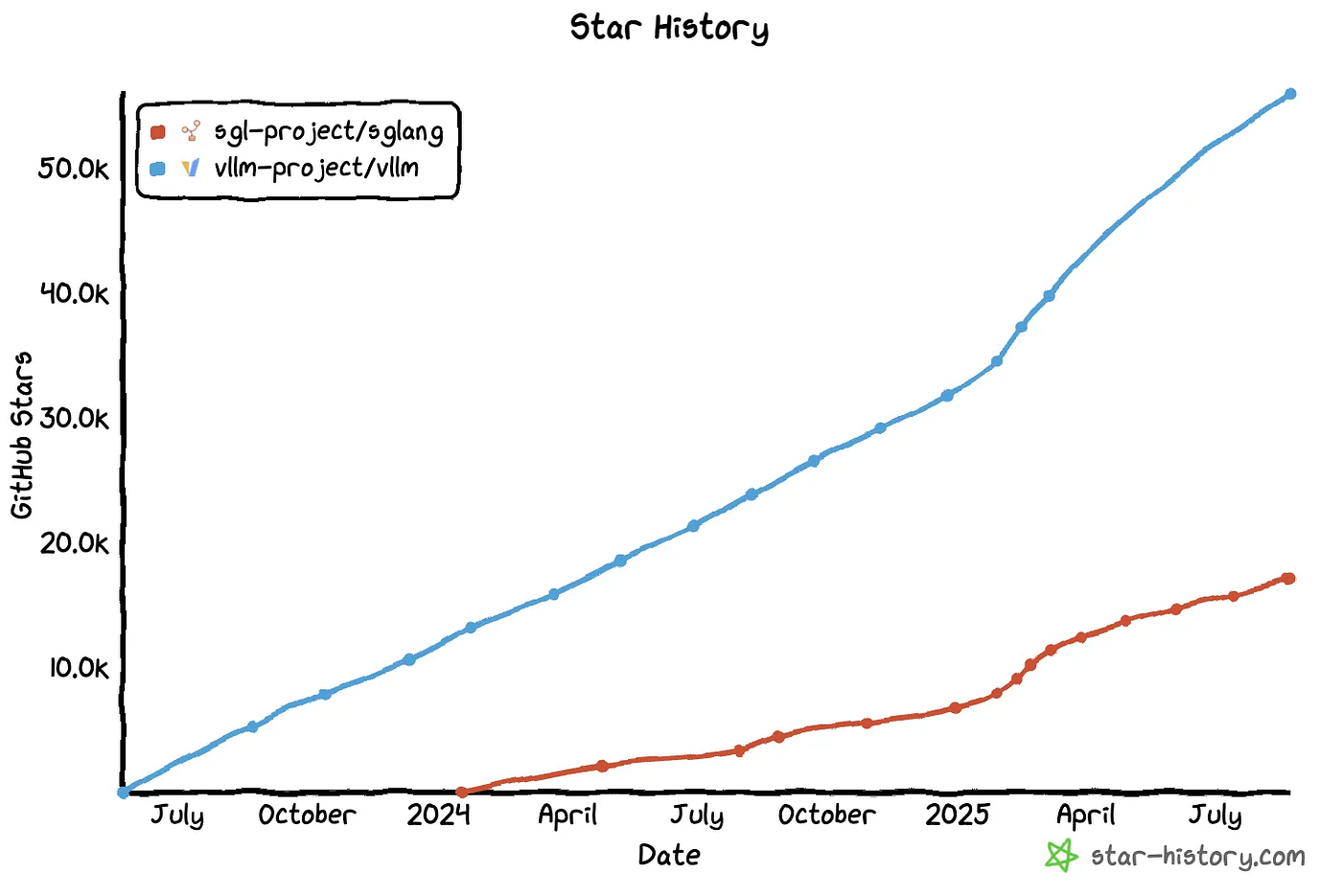
(Source: star-history)
vLLM delivered striking gains: compared with a Hugging Face Transformers–based backend, vLLM handled up to 5× the traffic and boosted throughput by as much as 30×. Within less than half a year it amassed tens of thousands of stars; today, over ten thousand contributors have engaged in issue/PR discussions, nearly 2,000 have submitted PRs, and on average at least 10 new issues are filed daily.
SGLang originated from the paper "SGLang: Efficient Execution of Structured Language Model Programs" and opened new ground with a highly optimized backend runtime centered on RadixAttention and an efficient CPU scheduling design. Rather than discarding PagedAttention, RadixAttention extends it: it preserves as much prompt and generation KV cache as possible and attempts to reuse KV cache across requests; when prefixes match, it slashes prefill computation.
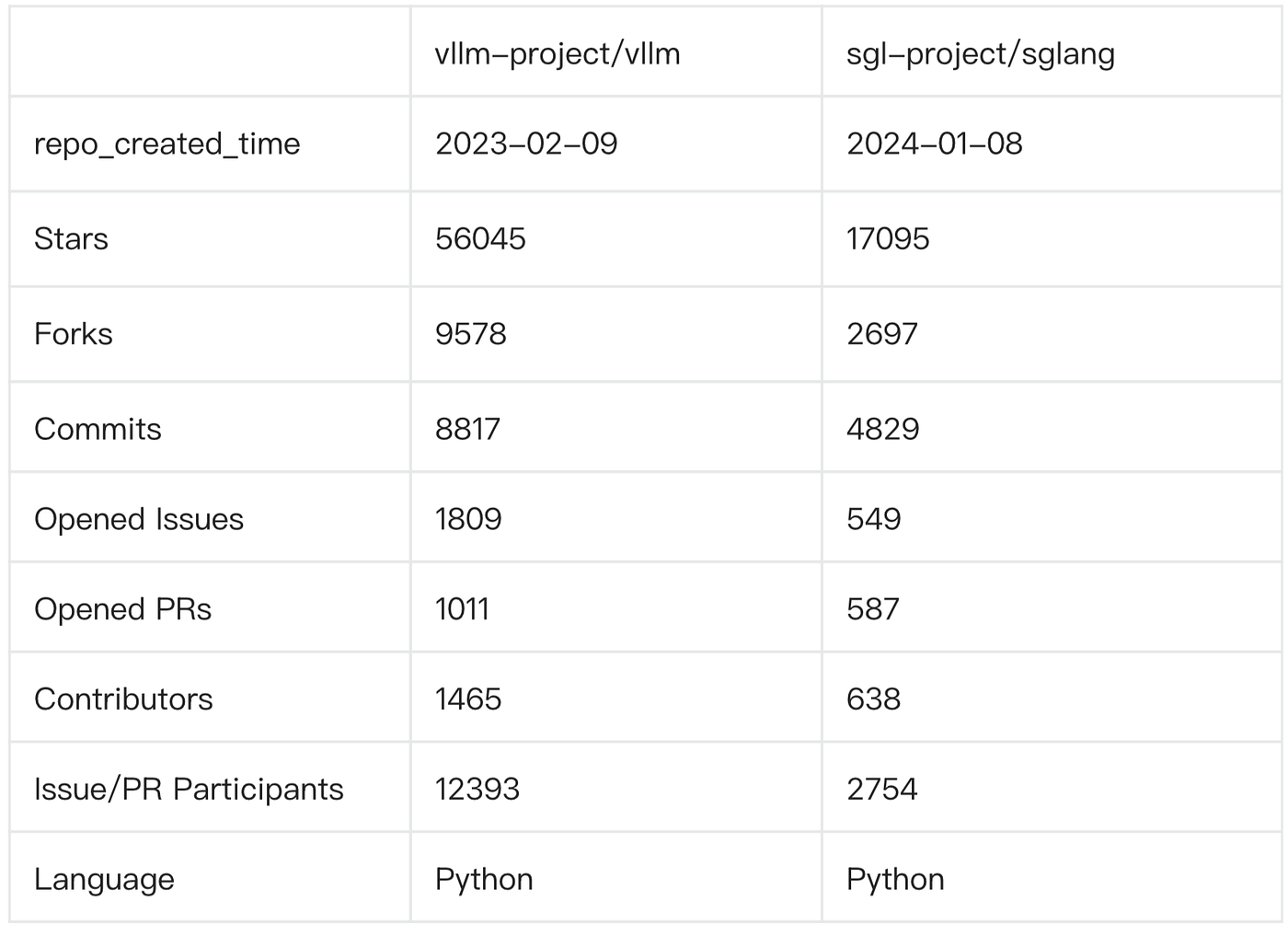
(Current community metrics for both projects, data as of August 22, 2025)
Community-wise, SGLang is a fast-rising newcomer with a leaner footprint — its total contributor count is less than half of vLLM's. Most issues in vLLM receive responses within 12 hours to 3 days, whereas in SGLang it typically takes 3 to 5 days.
Origins: a continuous current of innovation
As a leading U.S. public research university, UC Berkeley has produced a remarkable roster of open-source projects: Postgres in databases, RISC-V in hardware, Spark in big-data processing, and Ray in machine learning. Early core initiators of the two projects — Woosuk Kwon (vLLM) and Lianmin Zheng (SGLang) — both hail from Berkeley and studied under Ion Stoica, the luminary who led students to create Spark and Ray.
vLLM led the way with an open-source release in June 2023; SGLang debuted roughly six months later. In 2023, Lianmin, Stanford's Ying Sheng, and several scholars founded the open research group LMSYS.org, launching popular projects such as FastChat, Chatbot Arena, and Vicuna.
Today, core initiators Woosuk and Lianmin remain actively involved. Recent six-month contributor data show that early-career academic researchers remain a major force. Beyond academia, vLLM's contribution backbone includes Red Hat, while SGLang's core contributors come from xAI, Skywork, Oracle, and LinkedIn.
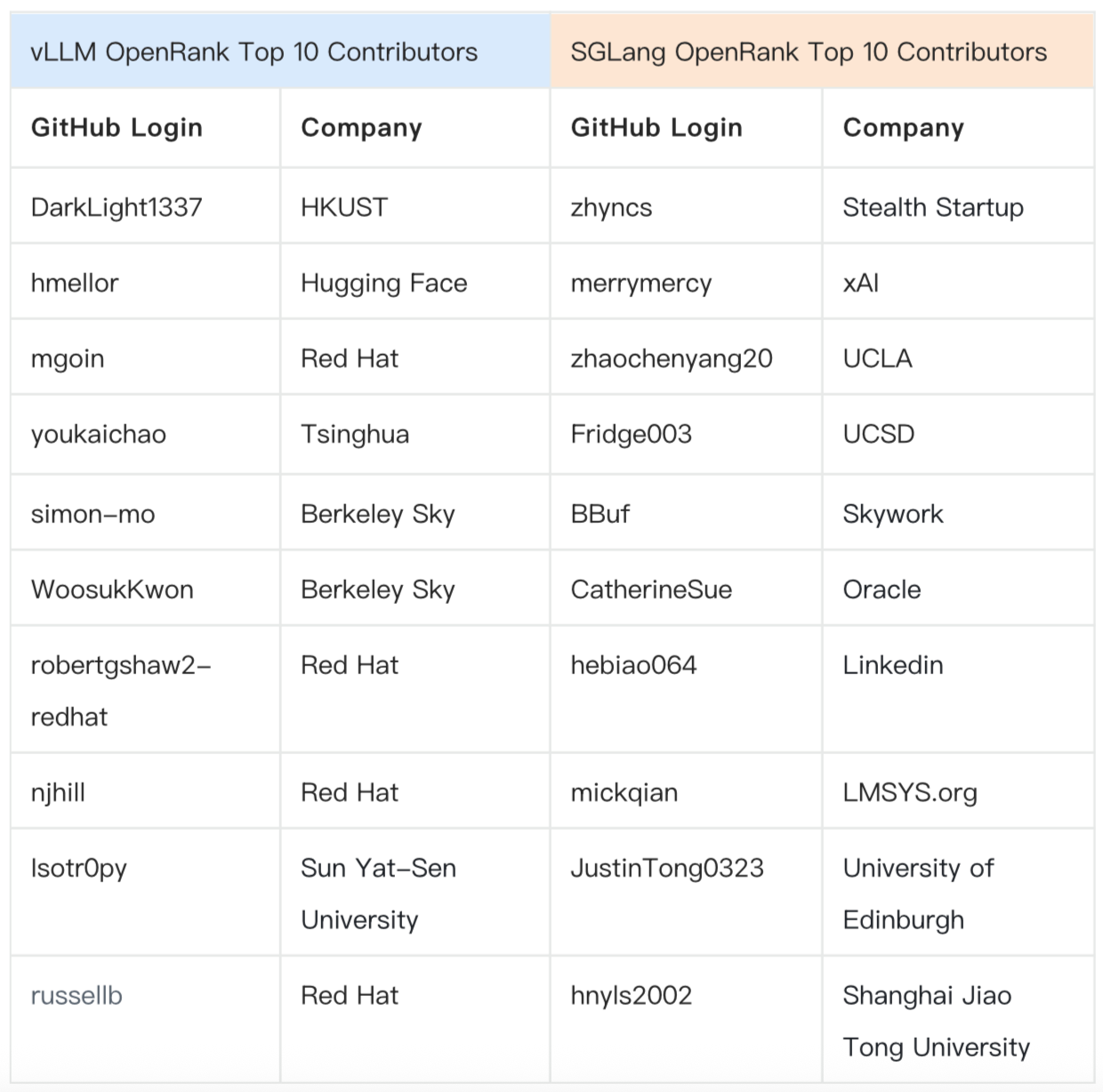
As many as 194 developers have contributed code to both vLLM and SGLang — about 30% of SGLang's total code contributors to date. Notable cross-contributors include:
- comaniac (OpenAI): 17 early PRs to SGLang + 77 PRs total to vLLM
- ShangmingCai (Alibaba Cloud Feitian Lab): 18 PRs to vLLM, then shifted focus to SGLang with 52 PRs
- CatherineSue (Oracle): 4 bug-fix PRs to vLLM, then 76 PRs to SGLang as a core contributor
Development, refactors, and fierce competition
Key milestones from an OpenRank perspective:
- June 2023: vLLM officially launches, introduces PagedAttention, and grows quickly.
- January 2024: SGLang ships its first release and gains industry attention thanks to RadixAttention.
- July 2024: SGLang releases v0.2, entering its first acceleration phase.
- September 2024: vLLM ships v0.6.0, cutting latency ~5× and improving performance ~2.7× via CPU-scheduling and other optimizations; SGLang releases v0.3 the day before.
- December 2024–January 2025: vLLM unveils the V1 refactor. With DeepSeek V3/R1 bursting onto the scene, both begin a second wave of explosive growth.
In 2024, as features and hardware support expanded rapidly, vLLM hit classic software-engineering headwinds. A third-party performance study published in September showed that in some scenarios vLLM's CPU scheduling overhead could exceed half of total inference time. The official blog acknowledged the need for a foundational refactor: V1 arrived in early 2025, after which growth re-accelerated.
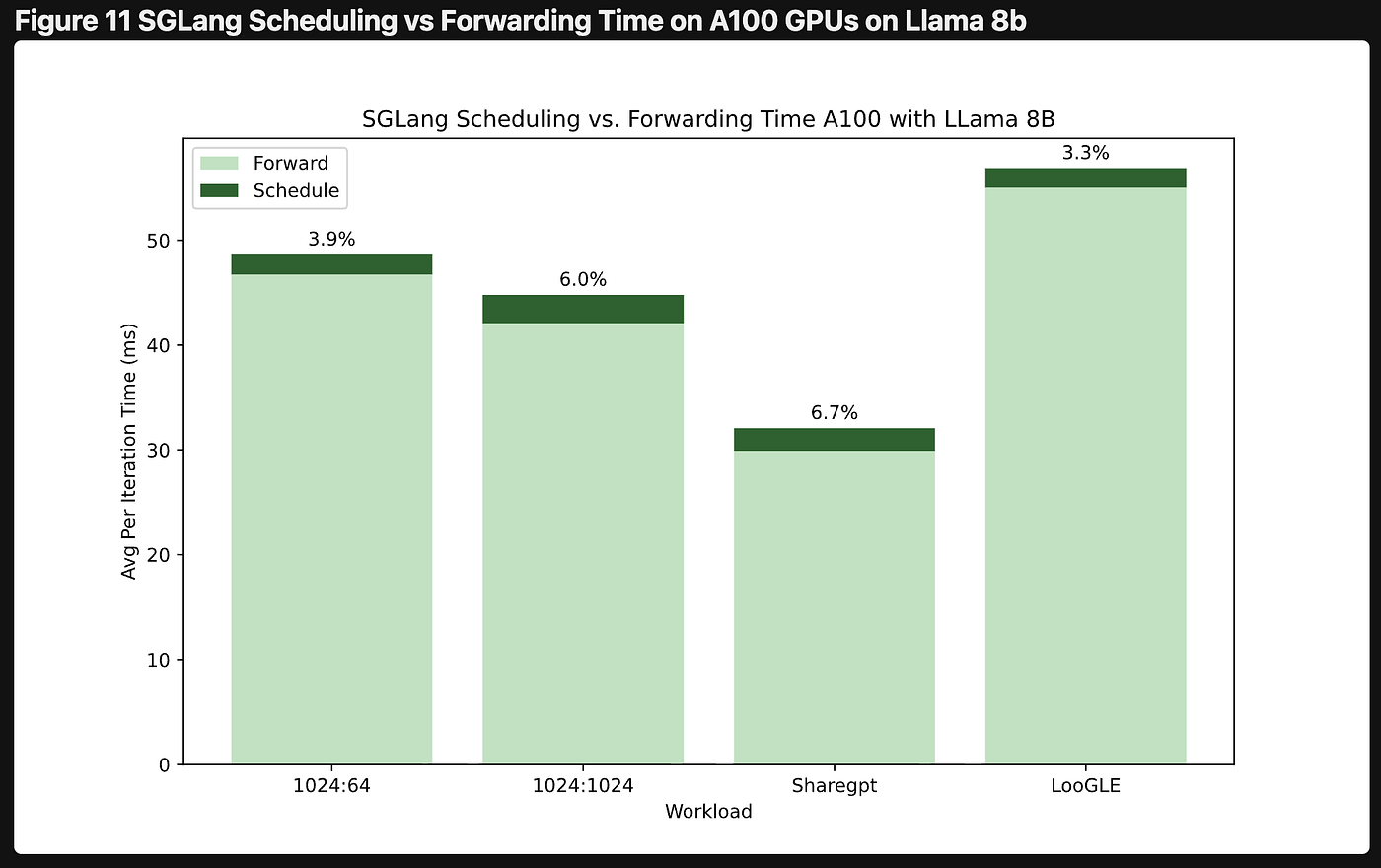
CPU scheduling overhead: vLLM (left) vs. SGLang (right)
In 2025, the performance race among inference engines heated up. Recognizing the limits of "number wars," both gradually shifted to reproducible methods and end-to-end metrics. A recent third-party comparison from Alibaba Cloud benchmarking vLLM vs. SGLang on the Qwen family showed overall single-GPU/dual-GPU results favoring SGLang, though outcomes vary across hardware/models/configurations.
Trend-wise, model architectures are showing signs of convergence. Leaders vLLM and SGLang now both support Continuous Batching, PagedAttention, RadixAttention, Chunked Prefill, Speculative Decoding, Disaggregated Serving, and CUDA Graphs; operator libraries like FlashInfer, FlashAttention, and DeepGEMM.
Other inference engines to watch:
- TensorRT-LLM: launched by NVIDIA in late 2023, deeply tuned for its own hardware
- OpenVINO: developed by Intel, focused on efficient deployment across Intel CPUs/GPUs
- Llama.cpp: written in C++ by Georgi Gerganov in 2023, targets low-barrier edge inference
- LMDeploy: co-developed by the MMDeploy and MMRazor teams, with dual backends — TurboMind for high performance and PyTorch for broad hardware coverage
Moving Forward in the Ecosystem
During their rapid-growth phase, both vLLM and SGLang drew attention from investors and open-source foundations:
- In August 2023, a16z launched the Open Source AI Grant, funding vLLM core developers Woosuk Kwon and Zhuohan Li. In a later cohort, SGLang core developers Ying Sheng and Lianmin Zheng were also funded.
- In July 2024, ZhenFund donated to vLLM, and LF AI & Data announced vLLM's entry into incubation; this year vLLM was moved under the PyTorch Foundation.
- In March 2025, PyTorch published a blog post welcoming SGLang to "the PyTorch ecosystem."
Both projects have become go-to inference solutions globally, with active participation from engineers at Google, Meta, Microsoft, ByteDance, Alibaba, Tencent, and other companies.

(Data Source: ossinsight) Company Backgrounds of Developers Submitting Issues
Today, roughly 33% of vLLM's contributors are based in China, and about 52% for SGLang. Both communities host regular in-person meetups in Beijing, Shanghai, Shenzhen, and other cities worldwide.